Deep Linking and Deeper
Linking:
Getting the Most out of
Existing Search Applications
Stephen P. Morse
This article first appeared in the Association of
Professional Genealogists Quarterly (March 2007).
It was reprinted in Avotaynu, the International Review of Jewish Genealogy (November 2007)
My
website at http://stevemorse.org consists
of web-based tools that I’ve developed.
Many of those tools use deep linking to allow you to search databases on
other websites in ways not possible by visiting those websites directly. To the uninitiated, what I do looks almost
like magic. That point was brought home
one day when I gave a lecture on my tools and someone in the audience asked:
“Can you develop a tool that lets us do a search in the 1890 census that was
destroyed in a fire?” The person asking
the question was dead serious, and he really believed that I could produce such
a tool.
Then
and there I realized that I needed to explain deep-linking in terms that a lay
person could understand, making it clear what sorts of things are possible and
what are not. That’s why I wrote this
paper. And by the way, it is not
possible to use deep linking to search in the 1890 census!
The
purpose of this paper is not to make you an expert in doing deep linking. Rather it is to give you an appreciation of
what deep linking is and what it can do.
Think of this as watching a magician perform. You know you won’t be able to perform the tricks yourself, but
none-the-less you can be awed at the kinds of tricks he can perform. And just to whet your appetite, he might
even teach you how to do some of the simpler tricks. I’ll do the same, and show you a simple method of deep linking
that you can do yourself. Beyond that,
don’t attempt to do the more advanced tricks (unless you have a background in
computers, and Internet protocols in particular), but simply go “ooh” and “ah”
as I describe my tricks.
What
is Deep Linking?
Deep
linking is linking to any page on another website other than the front
page. So the next question should be
“What is linking?”
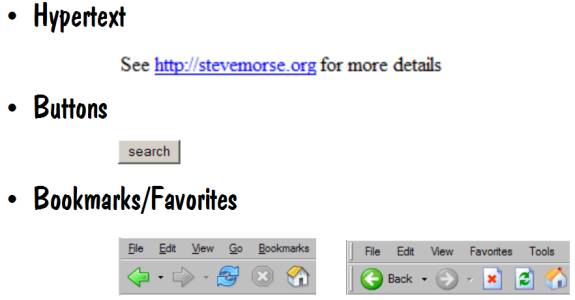
Linking
is what we do everyday and what the World Wide Web is based on. For example, when we see hypertext and click
on it, we are linking. When we see a
search button and press it, we are linking.
And when we bring up our set of bookmarks (a.k.a., favorites) and select
one, we are linking. There is nothing
inherently bad about linking, and without it there would be no web. Examples of hypertext, buttons, and
bookmarks are shown below.
We
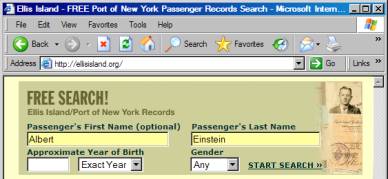
can classify linking as shallow linking and deep linking. Shallow linking would be linking to the
front page (or “home page”) of a website.
For example, if we went to http://ellisisland.org,
we are shallow linking. In this
particular example, we would get to the search form for finding passengers in
the Ellis Island database.
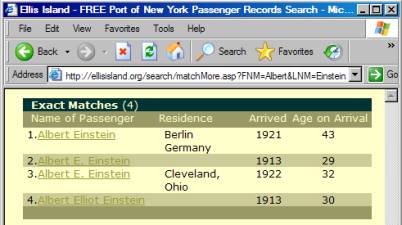
On
the other hand, if we went to http://www.ellisisland.org/search/matchMore.asp?FNM=Albert&LNM=Einstein,
we would get the results of a search for Albert Einstein. The website might have preferred that we
start with their search form and let them take us to the results. But there is no reason that we can’t go to
the results directly if we know what it is that we are searching for. This is deep linking.
We
can link even deeper and go to
http://www.ellisisland.org/cgi-bin/tif2gif.exe?T=\\192.168.100.11\images\T715-2945\T715-29450481.TIF. In this case we would obtain the image of the ship manifest for
Albert Einstein. This is undoubtedly
something the website didn’t want us to do, as evidenced by the fact that they
didn’t make this address visible when we navigated to the image in the manner
that they have prescribed for us.

What
is a Search Application?
Probably
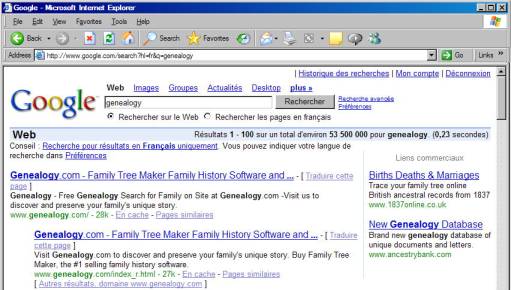
the most well-known search application is google. Their homepage, with their search form, is at http://www.google.com and looks like this:

If
we use their form to do a search on the word “genealogy”, we get the following
results:
![]()
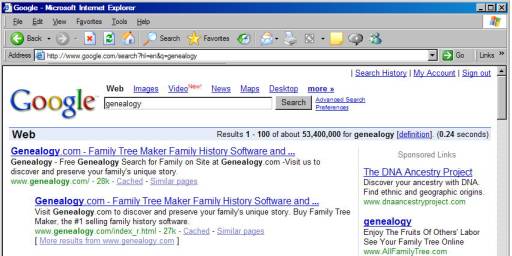
Although
we started by visiting their homepage to get to the search form, they took us
to a different page in order to present the results. The page that they took us to was http://www.google.com/search?hl=en&q=genealogy. Note the strange things following the
question mark in that page’s address.
In order to understand what they are, we need some definitions.
URL
Loosely speaking, a URL is an address of a web page. It stands for Uniform Resource Locator. But never mind what it stands for – those
terms are rather meaningless, even for someone in the computer field. Just remember that a URL is the address of a
web page.
Query String
A
query string is the portion of a URL following the question mark, if
any. It contains parameters
separated by ampersands (&).
As
an example, consider the address of the webpage that contains the results of
the google search for genealogy. The
URL is http://www.google.com/search?h1=en&q=genealogy. The query string is
h1=en&q=genealogy. And the
parameters are hl=en and q=genealogy.
With
this as a framework, we are ready to present the first method of deep linking.
URL Editing
Let’s describe this by using the google example we saw previously. In that example we noticed that the URL
contained a query string having the following parameters.
hl=en
q=genealogy
What
do these parameters mean? The q
parameter is obvious – it is the string being searched for. But what could the hl parameter be? Could “en” refer to English?
To
find out, let’s try changing the hl parameter from “en” to “fr” and see what
happens. That is, let’s move our cursor
to the address line and edit it by changing the “en” to “fr”, and then press
the enter key. The result is the
following:
Notice
that the page is now in French, or at least the google text on the page is
(Recherche avancée instead of Advanced Search). Of course the contents of the websites found are still in English
because they are indeed English language websites.
This
is a trick that you can do yourself. Go
to various search websites and look at the URL they generate for their search
results. If it contains a query string,
try changing the values of some of the parameters and see what happens.
Using your own
Search Form
URL
editing can be tedious and is error prone.
It’s certainly not the way that one website deep-links to another. Instead a deep-linking website will present
a search form that has the capability of generating the URL and query string
desired.
As
an example, consider the following form:
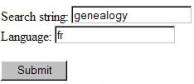
What
you see on this form is a place to enter genealogy and fr. This will obviously be used in some way to
generate the URL for the google example, with the parameter values being what
the user enters on the form. But there
are several things we need for that URL which you don’t see on the form. For starters, we need to know the names of
the two parameters – hl and q. They
appear nowhere on the form above. Also
we need to know the location of the google search engine (http://www.google.com/search) that will
generate the results for us.
These
parameter names and the search engine location are in the coding of the form –
they are just not visible on the screen.
And there’s no reason for them to be visible since they don’t affect the
way the user fills out the form.
The
way the form works is that when the user presses the “Submit” button, control
goes to the search engine specified in the form and the values that the user
entered on the form appear in the query string. In other words, the form will generate the same URL that we so
painstakingly edited above, and then it will send the browser to that location.
How to determine
Parameters
In
the above example we saw that google was expecting query string parameters of
hl and q. The particular names and
values of the parameters are unique to each website. Before we can use URL editing or search forms to get more out of
a website, we need to know the names and values of the parameters that the
website is expecting.
Here
are several ways of determining the parameters for a website:
URL
Viewing:
The
simplest way is to look at the query string that the website’s own search form
generates. This is what we did in the
google example presented above. But it
only shows us the parameters generated for the particular search that we made,
and does not show us possible parameters that it might generate in other
circumstances.
Code
Reading:
With
a little more difficulty we could look at the source code of the website’s
search form to see all the parameters that it could ever generate. This could reveal more parameters than was
possible by viewing the URL, but it still does not give all possible
parameters. For example, there might be
certain parameters that the website’s search engine is prepared to accept but
the website’s search form never generates.
These stealth parameters are the very ones that we want to take
advantage of to do more powerful searches than the website’s own form does.
Guessing:
We
could try guessing for some secret parameters.
Suppose we’ve already determined that the website accepts parameters of
fname (for first name) and lname (for last name). In that case we might try sending it a parameter of mname (middle
name) and see what happens. If it
changes the search results, we have probably found a hidden parameter that we
can take advantage of.
As
an example, by URL Viewing we notice that most of the parameters passed to http://ancestry.com are of the form fx where x
is a number. Suppose we’ve learned that
f3 is the street, f4 is the city, and f6 is the state. But we don’t find any cases in which they
generate an f5 parameter. So we can try
passing it an f5 parameter and experiment with different possible values to see
how it affects the results. After doing
so, we might be able to conclude that f5 is the county.
Sniffing:
This
is the most difficult method of determining parameters, and involves
specialized tools. A sniffer is a tool
that allows you to see the raw traffic going down the wires and to analyze it. By studying the raw bits and bytes, you can
determine the parameters that might not have been apparent by one of the other
methods.
Using a Search
Form without a Query String
To
illustrate this method, let’s do a phone-book lookup using http://anywho.com, which is AT&T’s online
phone directory.
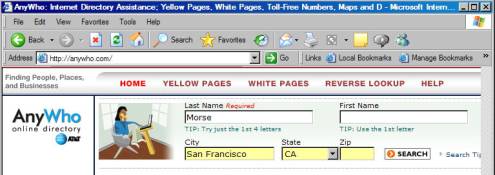
If
we fill in the form found on their website and press the search button, we get
to the following results page:
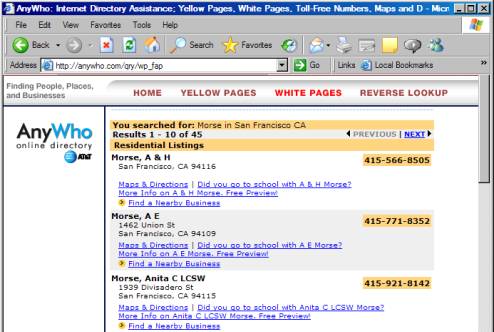
There are the results all right, but where is the query string? Notice that the URL in the address field is http://anywho.com/qry/wp_fap and does
not contain a question mark. So how
does the website know the name that you want it to look for?
To
answer that question, we have to learn about the methods used to pass
parameters to websites. There are two
methods, and they go by the name of GET and POST. But these names are meaningless even to computer professionals,
and I’d like to refer to them by more descriptive names such as OVERT (for GET)
and COVERT (for POST).
The
OVERT method is the most common one, and is used by default if a search form
does not specify a method. In this
case, the parameters are passed in the query string as we have already seen.
The
COVERT method still needs to send the parameters down the wires to the website
when making the search request. But it
doesn’t put them in the visible query string.
Instead it passes them silently in what is called the header section of
the request. The information goes down
the wires, but it’s not displayed in the address field. You might think that this method was devised
to keep you from seeing the parameters and doing deep linking. Although it has this unfortunate affect, the
purpose of the COVERT method is to allow you to pass more parameter information
than could have been possible with the OVERT method.
In
the case of anywho.com, the COVERT method was used. So we cannot deep link to this website by doing URL editing. But we can still deep link by developing our
own search forms that explicitly specify the COVERT method.
Man in the Middle
What
we’ve seen up until now has been rather static. Whatever results the website sends back are displayed on the
screen as is. By contrast, a man in the
middle provides a more dynamic capability.
Some of the things it can do are:
-
Modify the search results before the user sees them
-
Reformat the display of the results
-
Filter the results using additional search parameters
-
Display more results per page
The man in the middle is not
really a man but rather is a program that runs on some server out in
cyberspace. It is placed between the
user and the website so that it can do any or all of the things mentioned
above.
As an example, let’s
consider the results obtained when doing a search at http://ellisisland.org. Here are the results presented by that
website:
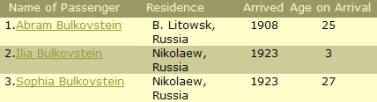
If you clicked on a
passenger’s name, you would be taken to a so-called passenger record, which
consists of all the transcribed information about that passenger. From the passenger record you could click on
another link that would take you to a textual version of the manifest page on
which the passenger appears. And from
the textual manifest page you could click on yet another link that would take
you to a scanned image of the actual manifest page.
I already had my own search
form that deep-linked into the Ellis Island database using the deep-linking
techniques previously described. But
now I wanted to modify the display of results so that a user could go directly
to the scanned manifest image with a single click and not need to first visit
the passenger record and then the textual manifest. The display I wanted was the following:
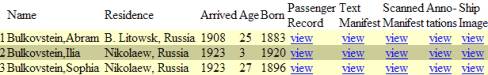
So I implemented a
man-in-the-middle program that would do the necessary reformatting and provide
the direct links. Notice that it also
added a field for year of birth, which it calculated by subtracting the age
from the year of arrival.
It’s interesting to note
that I added the above feature in August of 2002. Two years later the Ellis Island website added direct links to
their output, resulting in a display very similar to mine. Imitation is the sincerest form of flattery!
So how exactly does the man
in the middle approach work? Here’s a
diagram showing what happens when you make a request to a website.
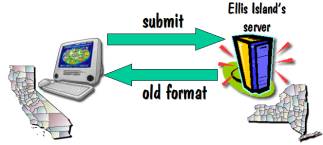
Suppose you are sitting in
California and you want to make a search request of the Ellis Island database,
which is housed on a server in New York.
Your browser submits the request, the Ellis Island server searches their
database to find the matches, and it then sends back a response as a web page
that gets displayed on your screen.
I’ll refer to that response as being in the “old format”.
Now let’s put a man in the
middle as shown in the next diagram.
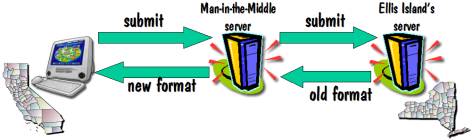
Now your browser submits the
search request to the man in the middle server which could be anywhere in the
world (in fact, the original man in the middle for my Ellis Island search form
was in France), and it in turn resubmits that same request to the Ellis Island
Server in New York. The Ellis Island
server sends the response back to its client, which is the man in the
middle. The man then reformats the
display into what I’ll refer to as the “new format”, and sends that back to you
in California for display on your screen.
Let’s look at another
example. The Israeli telephone company
is called Bezeq. They have a website at
http://www.144.bezeq.com that allows
you to search the Israeli telephone directory.
The problem is that it is all in Hebrew. Here is an example of search results that you get when using the
Bezeq website directly:

And here’s what you get when
you use a man in the middle that I created.
Note that on-the-fly it translated the words in the heading line and
transliterated the names in the result lines.

Yet another example is the
now-defunct http://anybirthday.com
website. This website allowed you to
enter a person’s name and it would search for his or her birthday. The search form that they presented was the
following
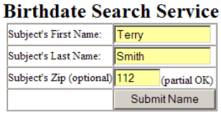
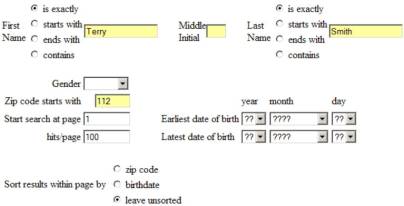
whereas the search form that
I created to access their data was:
Here is the display obtained
when using the anybirthday.com website directly:
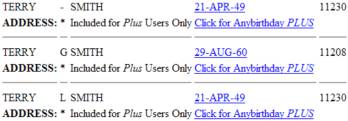
and here is the display when
using my man in the middle:

There are several points to
note from this example:
The only search parameters you could enter on the anybirthday.com search form was first name, last name, and zipcode. My form allowed you to enter some additional parameters such as middle initial and birthdate range. The results that anybirthday.com returned included this information, so my man in the middle was able to filter out any results not meeting these additional constraints.
My
form allowed you to enter gender as a search parameter. That’s certainly useful when searching on a
name like Terry. Although
anybirthday.com’s display did not include gender, it turns out that the
response they generated had the gender buried within it. My man in the middle was able to extract the
gender information from their response.
My
man in the middle was able to do additional reformatting such as sorting the
results by zipcode or birthdate.
My
man in the middle removed a lot of the noise from the display, making it easier
to read.
Although the anybirthday.com
website is no longer available, there are now replacement websites. On my website I have search forms and men in
the middle that search those replacement websites.
Complete Takeover
The man in the middle is a
one-time thing. The search form takes
the user to the man who in turn does his thing and eventually returns his
results to the user. After that, the
man is no longer in the picture.
A complete takeover involves
putting a man in the middle and keeping him there. As before, the search form takes the user to the man, and the man
fetches the first page from the actual website. In addition to doing the modifications described above, the man
can also change all links on that page so they point back to the man rather
than to the actual website. By doing
so, the man will stay in the middle for all future accesses to that website.
As an example, let’s
consider http://ellisisland.org. That website does not work when using the
old Netscape 4 browser. Here is what
you should see when visiting the website:
However here is what you see
when visiting the website with the Netscape 4 browser:
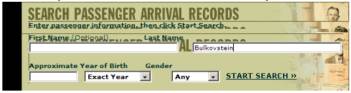
Although the screen display has been messed up, you can still read it, enter information, and even click on the “Start Search” link. But when you click on that link, what you get is a blank turquoise screen.

This happens because there
is an error in the code on the ellisisland.org website. They are missing what is referred to as a
closing table tag. Don’t worry about
what that means – you don’t have to understand it as long as I do. This error appears on all pages that they
return to you, so they obviously used a common template throughout their
website. Newer browsers are forgiving
of this error and are able to generate the correct display in spite of it, but
the old Netscape 4 browser is more demanding.
The cure is simple. The man in the middle can reinsert the
missing tag so the results page will display properly on your screen. But it must do this fix for all subsequent
accesses to the ellisisland.org website as well. That is, if you bring up the fixed page showing the passenger
record and then want to click the link on that page that takes you to the
textual version of the manifest, the fix needs to be applied to the text
manifest page as well. So the man in
the middle must remain in the middle after fetching each page. What is needed is a complete takeover. When the man in the middle fixes up any page
from the ellisisland.org website, it must also change all links on that page so
they point back to the man in the middle instead of to the ellisisland.org
website directly.
Admittedly the Netscape 4
browser is not widely used anymore, but it does provide a good example and
motivation for doing a complete takeover.
Logging In
Some websites require a user
to log in before he can see the search results that the website generates. When using a man in the middle, the man must
log in on behalf of the user. There are
several different mechanisms that a website could use for its log-in
procedure. These include:
Passing
the username and password as parameters
Juggling
something called cookies between the user and the final website
Something
called http authentication
Use of secure servers (https://)
None of these mechanisms
present insurmountable barriers to the man in the middle.
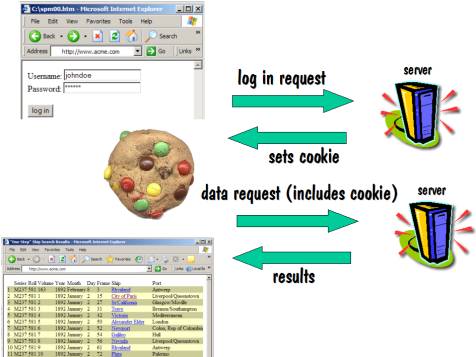
Let’s examine a login
involving cookies. In this case, the
user fills in his username and password on a form and sends that to the
server. The server responds by telling
the user’s browser to set a cookie. A
cookie is a piece of data stored on the user’s hard drive. When the user makes any further requests to
that same server, the user’s browser will send the contents of that cookie
along with the request. When the server
sees those contents, it knows that this user had already logged on, and will
allow the user to access the website’s data.
This is shown diagrammatically as follows:
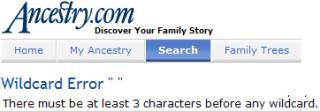
As an example, let’s
consider http://ancestry.com. Suppose we wanted to find all people in the
1930 census with a first name of Stephen and a last name starting with Mo. That search, if done directly from their
website, would produce the following results:
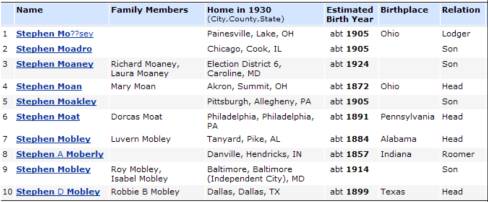
The man in the middle can
get around the three-character limitation by doing repeated searches on behalf
of the user and stitching the results together. That is, it first does a search for last names starting with Moa,
then Mob, up to Moz, and then seamlessly combines all the results into one
display so it appears to the user as though only a single search was done.
A problem with this is approach is that ancestry.com requires a login before it will return the results, and it uses cookies to know if you are logged in or not. So the man in the middle must know the contents of your cookie, and send those contents to the ancestry website when making the requests on your behalf.
It’s simple for you to
determine the contents of your cookies (there’s a short command that you type into
your browser’s address field to do so).
On my search form that deep links to the ancestry website, I had a field
in which you would enter the value of your cookie. And with this, my man in the middle was able to login and do the
26 searches for you. The results it
generated are shown here:
Another approach would be to
ask the user to fill in his username and password on my search form, and then
the man in the middle could log in on behalf of the user and obtain the cookie
directly. In some cases that would work
fine, but ancestry doesn’t permit logins with the same username from two
different places within a certain period of time (probably half an hour). So if the user had just logged in to
ancestry, the man in the middle would be prevented from doing so.
Unfortunately my
circumventing of the three-character requirement was tying up too much
bandwidth on the ancestry website, so they changed their login procedure to
make it more difficult for my man in the middle. I could have modified my man in the middle to use their new
procedure, but they would have simply changed the procedure again. Rather than getting involved in such a
cat-and-mouse game, I removed my ancestry.com man in the middle. Even though searching on less than three
leading characters is no longer possible, this example does illustrate the
power of the man in the middle and how it is able to log in on the user’s
behalf.
How to Block Deep Linking
Let’s switch hats now and
suppose that we have a website that we don’t want others to deep link to. After all, we worked hard to collect our
data and we don’t want other websites gaining access to it. Remember the golden rule – Do not let
other’s do unto you as you would do unto them!
There are several things
that a website can use to prevent others from deep linking to it. These are listed below:
Referrer Field
Whenever your browser fetches a page from a website, it tells that website the identity of the page that you are currently on. This is called the referrer, because it referred you to the website. For example, if page 1 contains a link to page 2 and you click on that link, the browser includes the URL of page 1 along with the request that it makes to page 2. Now the website can reject requests if the user is not on the website’s own search form when making the request. That would effectively block any other website from putting up a search form that deep links to this website.
This
method has one significant downside.
Not all browsers transmit the referrer field, and some browsers even
allow you to decide if you want the information transmitted or not. After all, there are some privacy concerns
involved when you tell a website where you came from. And if the browser does not transmit the referrer field, the
website cannot use this method of blocking deep linking.
Cookies
A website can write a cookie (piece of data) to your hard drive when you visit the website’s search form. Then when you submit the form to make a search request, the cookie gets transmitted back to the website along with the request. The only cookies sent to the website are those that the website itself has set – no other website’s cookies are sent. So the website can determine if you came from its search form by checking for the cookie.
Images
Some websites require a user to read a number found in a distorted image, and to type that number into one of the fields on a form. If the user is unable to supply the correct number, the request is denied. The idea here is that only a real person could read such images, and a man in the middle would not be able to supply the correct number.
As an example, there is a
website called http://jewishdata.com. One of the forms presented on their website
allows you to search for Jewish passengers in the Ellis Island database. Interestingly enough, I have such a form on
my website and I present the results by searching through data on my website (I
do not do any deep linking in this case).
The form on the jewishdata.com website looks very similar to my form,
and indeed the results page that it displays is the results page that my
website generates. And although I’ve
never heard of the people who run this website, at the very bottom of their
form they cite me and say “used with permission”.
Well of course I can’t allow
others to deep link to my website, so I had to put a stop to it. I did so by using a modified version of the
cookie technique described above. But
then I had to decide what to do when I detected such a deep-linking
attempt. Many websites react to such
attempts by returning a page that says something like “invalid access”. But I decided to be clever about it. Instead of giving such a rude message, I
redirect the user to my search form on my website, and it comes up prefilled
with all the information that he entered on jewishdata.com’s search form. I’ve effectively hi-jacked their user and he
has now become my user. At this point
he can make the search request, and he’s forgotten all about jewishdata.com.
Defeating the Deep Linking Block
Now let’s put our original
hat back on, and continue creating websites that deep link to other
websites. We’ve come across a website
that has installed a technique to block us, such as one of those presented in
the previous section. What do we do?
Is it possible to defeat the
deep linking block? The answer is
yes. So how do you do it? Unfortunately, if I told you I would have to
kill you. We would be getting into a
spy-versus-spy game here. I don’t want
anyone defeating the deep link blocking that I’ve installed on my own website.
But I will give you an
example of something that I’ve done to defeat a block from a website that I was
trying to deep link to. The website was
http://travelgis.com, and they present
latitude and longitude information that I was making use of. At first it was very easy to deep link to
their website, but then they decided to raise the bar. They added a numeric image on their website,
and refused entry to anyone who couldn’t read that number. Here is what their website now looks like:
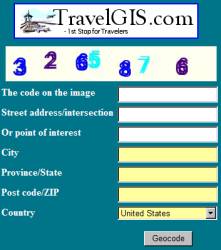
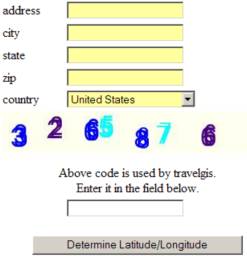
That was too easy to
defeat. My man in the middle simply
included that same image on the page that it presented to my users, and I
relied on my own users to decipher the image for me.
Is Deep Linking Legal?
With all this fuss over deep
linking and websites trying to block it, the obvious question comes about as to
whether deep linking is legal. As I
mentioned at the beginning, the entire World Wide Web is based on the concept
of deep linking, and without it the web would become a very sterile place.
I’m not a lawyer, so what I
present here should not be construed as a legal opinion. But it is the result of some of my own
research on the subject.
The first example of a
deep-linking lawsuit that I was able to find occurred in Scotland in 1997. It involved the Shetland Times and the
Shetland News. Both were newspaper
websites that presented daily news stories on line. The original stories were in the Times and consisted of headlines
that linked to the actual stories. Each
day the News would copy the headlines from the Times, place those headlines on
its own website, and have each headline deep-link to the story on the Times’
website. These links bypassed the Times
homepage that had advertising on it, so the Times was not too happy about this.
The case went to court. The court banned the links based on the fact
that the News was using the Times headlines verbatim. The News did not alter the wording of the Times headlines, so
this was considered a copyright violation.
By giving the verdict in this manner, the court avoided having to rule
on the deep linking issue.
The next case I found
involved Ticketmaster and Microsoft.
Microsoft operated a website called Sidewalk, which was a recreational
and cultural guide for various cities.
Sidewalk offered users a link to Ticketmaster to buy tickets for events
in the particular city. The links
promoted Ticketmaster sales by sending them customers that they might not have
had otherwise. Ticketmaster ignored the
increase to their bottom line and decided to sue. They were more interested in having their day in court than in
making additional sales. But Microsoft
had much deeper pockets than Ticketmaster, so the case was eventually settled
out of court with the terms kept sealed.
No judicial ruling was issued.
Ticketmaster wasn’t happy about this, so they decided to try again. This time they focused on Tickets.com who was doing exactly the same thing that Microsoft did. And Tickets.com’s pockets weren’t as deep as Microsoft’s. This time the case went to court, and the court ruled against Ticketmaster. The court’s ruling included the following statements:
“Hyperlinking
does not itself involve a violation of the copyright act since no copying is
involved.”
“There
is no deception in what is happening.”
As I said before, I’m not a
lawyer. But the conclusions from this
court statement seem obvious to me.
Summary
In this article we learned
about the following methods of deep linking and how to prevent them:
URL
Editing
Using
a Search Form
Search
Form without a Query String
Man
in the Middle
Complete
Takeover
Blocking
Deep Linking
Preventing
Blocking of Deep Linking
Many examples were
given. For still more examples I
recommend looking at my website which contains over 100 web-based tools, many
of which do deep linking. My website is
at http://stevemorse.org.